You have probably come across terms like weights and bias when exploring neural networks. Neural networks can discover patterns that weights by themselves cannot achieve. This is accomplished by modifying the activation function using bias. Although weights are often emphasized, bias plays a crucial role in enabling the model to learn intricate patterns effectively. Nevertheless, bias is frequently overlooked.
In this article, we will discuss what bias is and its significance in neural networks. So let’s dive in!
Let’s consider a neuron within a neural network as a miniature calculator. It takes inputs, multiplies them by certain weights, adds a bias, and then transfers the outcome through an activation function.
In mathematical terms, the output from a single neuron can be expressed as:
y = f(WX + b)
where,
X = Input(s)
W = Weight(s) (indicating the significance of an output)
b = Bias (aids in modifying the output)
f = Activation function (introduces non-linearity)
Why is Bias Crucial?
The following points illustrate the significance of bias in Neural Networks.
1: It Aids in Shifting the Activation Function
Consider a straightforward neural network designed to predict whether it will rain or not.
If decisions are based solely on weights, the activation function will invariably originate at zero, implying that it will be aligned with the origin.
Bias permits the activation function to move left or right. This adjustment enables the network to align data more effectively.
In the absence of bias, all neurons would be compelled to pass through the origin (0,0), which restricts the model’s adaptability to learn from the data.
2: It Enhances the Model’s Pattern Learning Capability
Imagine you are training a deep-learning algorithm designed to recognize handwritten numbers. If the output of the neuron is:
y = W . X
It will invariably intersect the point (0,0) when X = 0. However, if the correct output does not equal zero, then Bias assists in adjusting the network’s output, making it better at discerning patterns.
Think of bias as the “starting point” of a function. Without it, every function would commence at zero, leading to a less adaptable learning process for the model.
3: Bias Functions Analogous to the Y-Intercept in a Linear Equation
You may have learned about the formula for a straight line presented as follows:
y = mx + c
where,
m (gradient) which can be regarded as coefficients.
c (y-intercept) can be viewed as the offset.
Based on the previously mentioned equation, if you eliminate c, the line is obliged to intersect at (0,0), which diminishes its adaptability.
Now let’s discuss the implications of omitting the Offset.
What Occurs If We Omit the Offset?
If the offset is set to zero, the network faces significant challenges in grasping complex patterns. Here are various complications that may arise:
The model may have difficulties with data that is non-zero-centered.
The duration of model training could extend beyond what is typical.
The network’s learning may be hindered, potentially leading to the adoption of a suboptimal solution.
How to Integrate Offset in PyTorch?
In PyTorch, the offset is typically included automatically in most neural network layers. However, you can modify, initialize, or even discard it based on your requirements. Let’s explore the ways to implement and manage offset in PyTorch with code snippets and their corresponding outputs.
Method 1: Utilizing Built-in PyTorch Layers
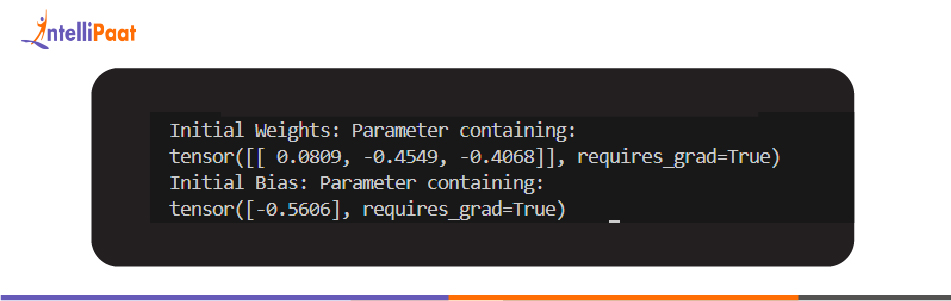
The majority of layers in torch.nn include an offset by default. Below is an illustration using nn.Linear:
Example:
Python
Code Copied!
var isMobile = window.innerWidth “);
editor10456.setValue(decodedContent); // Set the default text
editor10456.clearSelection();
editor10456.setOptions({
maxLines: Infinity
});
function decodeHTML10456(input) {
var doc = new DOMParser().parseFromString(input, “text/html”);
return doc.documentElement.textContent;
}
// Function to copy code to clipboard
function copyCodeToClipboard10456() {
const code = editor10456.getValue(); // Get code from the editor
navigator.clipboard.writeText(code).then(() => {
// alert(“Code copied to clipboard!”);
jQuery(“.maineditor10456 .copymessage”).show();
setTimeout(function() {
jQuery(“.maineditor10456 .copymessage”).hide();
}, 2000);
}).catch(err => {
console.error(“Error copying code: “, err);
});
}
function closeoutput10456() {
var code = editor10456.getSession().getValue();
jQuery(".maineditor10456 .code-editor-output").hide();
}
// Attach event listeners to the buttons
document.getElementById("copyBtn10456").addEventListener("click", copyCodeToClipboard10456);
document.getElementById("runBtn10456").addEventListener("click", runCode10456);
document.getElementById("closeoutputBtn10456").addEventListener("click", closeoutput10456);
Output:
Important points to remember:
bias=True ensures that the layer incorporates an offset term.
PyTorch automatically initializes the offset.
Clarification:
The aforementioned code establishes a basic linear layer in PyTorch. It consists of 3 input features and 1 output feature. It initializes its coefficients and offset, and displays them.
In certain situations (for instance: batch normalization or convolutional layers), the usage of an offset may be redundant. You can disable it by assigning bias=False.
Example:
Python
“““html
var isMobile = window.innerWidth “);
editor44067.setValue(decodedContent); // Assign the default text
editor44067.clearSelection();
editor44067.setOptions({
maxLines: Infinity
});
function decodeHTML44067(input) {
var doc = new DOMParser().parseFromString(input, “text/html”);
return doc.documentElement.textContent;
}
// Function to duplicate code to clipboard
function copyCodeToClipboard44067() {
const code = editor44067.getValue(); // Retrieve code from the editor
navigator.clipboard.writeText(code).then(() => {
// alert(“Code duplicated to clipboard!”);
function closeoutput44067() {
var code = editor44067.getSession().getValue();
jQuery(".maineditor44067 .code-editor-output").hide();
}
// Attach event listeners to the buttons
document.getElementById("copyBtn44067").addEventListener("click", copyCodeToClipboard44067);
document.getElementById("runBtn44067").addEventListener("click", runCode44067);
document.getElementById("closeoutputBtn44067").addEventListener("click", closeoutput44067);
Results:
When is it appropriate to exclude Bias?
If you are utilizing BatchNorm or LayerNorm (they manage bias internally).
Bias has negligible influence on specific convolutional architectures.
Clarification:
The preceding code establishes a linear layer devoid of a bias term in PyTorch. It outputs its bias which will be None because bias=False.
Method 3: Custom Initialization of Bias Values
Occasionally, you may wish to configure bias independently rather than relying on the default initialization.
Illustration:
Python
Code Duplicated!
var isMobile = window.innerWidth “);
editor87155.setValue(decodedContent); // Assign the default text
editor87155.clearSelection();
editor87155.setOptions({
maxLines: Infinity
});
function decodeHTML87155(input) {
var doc = new DOMParser().parseFromString(input, “text/html”);
return doc.documentElement.textContent;
}
// Function to duplicate code to clipboard
function copyCodeToClipboard87155() {
const code = editor87155.getValue(); // Retrieve code from the editor
navigator.clipboard.writeText(code).then(() => {
// alert(“Code duplicated to clipboard!”);
function
``````javascript
closeoutput87155() {
var code = editor87155.getSession().getValue();
jQuery(".maineditor87155 .code-editor-output").hide();
}
// Attach event handlers to the buttons
document.getElementById("copyBtn87155").addEventListener("click", copyCodeToClipboard87155);
document.getElementById("runBtn87155").addEventListener("click", runCode87155);
document.getElementById("closeoutputBtn87155").addEventListener("click", closeoutput87155);
Output:
Why should you Custom Initialize Bias?
It aids in preventing the gradients from vanishing in extensive networks.
It explores varied initialization strategies to achieve improved convergence.
Clarification:
The preceding code snippet is utilized to establish a layer in PyTorch. It sets its bias to 0.5 through the use of torch.nn.init.constant_, and subsequently outputs the modified bias value.
Method 4: Integrating Bias in Custom PyTorch Models
When crafting a personalized neural network, bias is inherently included in layers, granting you control over it.
Sample:
Python
Code Copied!
var isMobile = window.innerWidth “);
editor77898.setValue(decodedContent); // Set the default text
editor77898.clearSelection();
editor77898.setOptions({
maxLines: Infinity
});
function decodeHTML77898(input) {
var doc = new DOMParser().parseFromString(input, “text/html”);
return doc.documentElement.textContent;
}
// Function to duplicate code to clipboard
function copyCodeToClipboard77898() {
const code = editor77898.getValue(); // Retrieve code from the editor
navigator.clipboard.writeText(code).then(() => {
jQuery(“.maineditor77898 .copymessage”).show();
setTimeout(function() {
jQuery(“.maineditor77898 .copymessage”).hide();
}, 2000);
}).catch(err => {
console.error(“Error copying code: “, err);
});
}
function runCode77898() {
var code = editor77898.getSession().getValue();
jQuery(“#runBtn77898 i.run-code”).show();
jQuery(“.output-tab”).click();
jQuery.ajax({
url: “https://intellipaat.com/blog/wp-admin/admin-ajax.php”,
type: “post”,
data: {
language: “python”,
code: code,
cmd_line_args: “”,
variablenames: “”,
action:”compilerajax”
},
success: function(response) {
var myArray = response.split(“~”);
var data = myArray[1];
function closeoutput77898() {
var code = editor77898.getSession().getValue();
jQuery(".maineditor77898 .code-editor-output").hide();
}
// Attach event handlers to the buttons
document.getElementById("copyBtn77898").addEventListener("click", copyCodeToClipboard77898);
document.getElementById("runBtn77898").addEventListener("click", runCode77898);
document.getElementById("closeoutputBtn77898").addEventListener("click", closeoutput77898);
Output:
Key points:
Every nn.Linear layer has its own bias term.
It is possible to print, adjust, or deactivate bias for individual layers.
Clarification:
The above code snippet serves to define a custom neural network. It encompasses 2 layers (each possessing a bias). It is helpful for initializing the model and outputs the bias values associated with both layers.
Method 5: Bias in Convolutional Layers (nn.Conv2d, nn.Conv1d, etc.)
Convolutional layers inherently contain bias by default.
Sample:
Python
Code Copied!
“““javascript
isMobile = window.innerWidth “);
editor16148.setValue(decodedContent); // Establish the initial text
editor16148.clearSelection();
editor16148.setOptions({
maxLines: Infinity
});
function decodeHTML16148(input) {
var doc = new DOMParser().parseFromString(input, “text/html”);
return doc.documentElement.textContent;
}
// Function for copying code to clipboard
function copyCodeToClipboard16148() {
const code = editor16148.getValue(); // Retrieve code from the editor
navigator.clipboard.writeText(code).then(() => {
// alert(“Code copied to clipboard!”);
function dismissOutput16148() {
var code = editor16148.getSession().getValue();
jQuery(".maineditor16148 .code-editor-output").hide();
}
// Attach event listeners to the buttons
document.getElementById("copyBtn16148").addEventListener("click", copyCodeToClipboard16148);
document.getElementById("runBtn16148").addEventListener("click", executeCode16148);
document.getElementById("closeoutputBtn16148").addEventListener("click", dismissOutput16148);
Output:
Should bias be utilized in CNNs?
When using batchnorm, incorporating bias is essential.
Bias may enhance feature extraction in scenarios where datasets are limited.
Clarification:
The preceding code initializes a 2D convolutional layer. It consists of 3 input channels, 16 output channels, a 3×3 kernel, with bias enabled. Subsequently, it prints the bias values of the layer.
Method 6: Bias in Neural Networks with Various Initializations
In this section, we will assess different approaches for initializing bias in a PyTorch Model:
Example:
Python
Code Copied!
var isMobile = window.innerWidth “);
editor2324.setValue(decodedContent); // Establish the initial text
editor2324.clearSelection();
editor2324.setOptions({
maxLines: Infinity
});
function decodeHTML2324(input) {
var doc = new DOMParser().parseFromString(input, “text/html”);
return doc.documentElement.textContent;
}
// Function for copying code to clipboard
function copyCodeToClipboard2324() {
const code = editor2324.getValue(); // Retrieve code from the editor
navigator.clipboard.writeText(code).then(() => {
// alert(“Code copied to clipboard!”);
function dismissOutput2324() {
var code = editor2324.getSession().getValue();
jQuery(".maineditor2324 .code-editor-output").hide();
}
// Attach event listeners to the buttons
document.getElementById("copyBtn2324").addEventListener("click", copyCodeToClipboard2324);
document.getElementById("runBtn2324").addEventListener("click", executeCode2324);
document.getElementById("closeoutputBtn2324").addEventListener("click",
``````html
closeoutput2324);
Output:
Various Bias Initialization Techniques:
Zeros(init.zeros_)- This ensures that every neuron begins with an identical bias.
Normal Distribution(init.normal_)- Itintroduces variability to the bias for enhanced generalization.
Clarification:
The preceding code is utilized to initialize the bias of the initial fully connected layer (fc1) to zero. Subsequently, it initializes the second fully connected layer (fc2) by employing a normal distribution with a mean of 0.0 and a standard deviation of 0.1. Following that, it displays the revised bias values.
Method 7: Experiment: Assessing Networks With and Without Bias
Next, let’s examine the operation of a basic neural network with and without bias.
Illustration:
Python
Code Copied!
var isMobile = window.innerWidth “);
editor82548.setValue(decodedContent); // Establish the default text
editor82548.clearSelection();
editor82548.setOptions({
maxLines: Infinity
});
function decodeHTML82548(input) {
var doc = new DOMParser().parseFromString(input, “text/html”);
return doc.documentElement.textContent;
}
// Function to copy code to clipboard
function copyCodeToClipboard82548() {
const code = editor82548.getValue(); // Acquire code from the editor
navigator.clipboard.writeText(code).then(() => {
// alert(“Code copied to clipboard!”);
function closeoutput82548() {
var code = editor82548.getSession().getValue();
jQuery(".maineditor82548 .code-editor-output").hide();
}
// Attach event listeners to the buttons
document.getElementById("copyBtn82548").addEventListener("click", copyCodeToClipboard82548);
document.getElementById("runBtn82548").addEventListener("click", runCode82548);
document.getElementById("closeoutputBtn82548").addEventListener("click", closeoutput82548);
Output(Results may differ):
Findings and Observations:
The model with bias typically attains a reduced loss compared to the model without bias.
Bias aids in shifting the activation function, thereby enhancing the model’s learning efficacy.
Concluding Remarks:
In PyTorch, managing, adjusting, and experimenting with Bias in neural network models is straightforward.
By default, most layers are equipped with bias.
Bias can be disabled, altered, or initialized manually.
Bias contributes positively to learning, especially in deep networks.
How Do Various Weight Initializations Affect Bias?
Now, let’s delve into how bias is influenced by different weight initialization methods.
Setting all weights to zero means that all neurons will converge on the same information, rendering the network ineffectual.
Illustration:
Python
Code Copied!
var isMobile = window.innerWidth “);
editor66119.setValue(decodedContent); // Set the default text
editor66119.clearSelection();
editor66119.setOptions({
maxLines: Infinity
});
function decodeHTML66119(input) {
var doc = new DOMParser().parseFromString(input, “text/html”);
return doc.documentElement.textContent;
}
// Function to copy code to clipboard
function copyCodeToClipboard66119() {
const code = editor66119.getValue(); // Retrieve code from the editor
navigator.clipboard.writeText(code).then(() => {
// alert(“Code copied to clipboard!”);
The aforementioned code is designed to establish a basic layer in PyTorch. This layer initializes both weights and bias to zero with the use of torch.nn.init.zeros_(). Subsequently, it outputs the initialized values.
Effects on Bias:
The bias component does not influence the differentiation of neurons as each neuron commences with identical weights.
Given that all neurons alter in the same way, the network struggles to acquire significant patterns.
Method 2: Random Normal Initialization
At times, initializing weights from a normal distribution can lead to gradient explosion or vanishing.
Illustration:
Python
Code Copied!
var isMobile = window.innerWidth “);
editor33802.setValue(decodedContent); // Set the default text
editor33802.clearSelection();
editor33802.setOptions({
maxLines: Infinity
});
function decodeHTML33802(input) {
var doc = new DOMParser().parseFromString(input, “text/html”);
return doc.documentElement.textContent;
}
// Function to copy code to clipboard
function copyCodeToClipboard33802() {
const code = editor33802.getValue(); // Retrieve code from the editor
navigator.clipboard.writeText(code).then(() => {
// alert(“Code copied to clipboard!”);
function closeOutput33802() {
var code = editor33802.getSession().getValue();
jQuery(".maineditor33802 .code-editor-output").hide();
}
// Bind event listeners to the buttons
document.getElementById("copyBtn33802").addEventListener("click", copyCodeToClipboard33802);
document.getElementById("runBtn33802").addEventListener("click", runCode33802);
document.getElementById("closeOutputBtn33802").addEventListener("click", closeOutput33802);
Results (values may vary):
Clarification:
The preceding code is utilized to set the weights and biases of a linear layer. It employs a normal distribution with a mean of 0 and a standard deviation of 1, subsequently displaying the initialized values.
Influence on Bias:
Bias may become ineffective due to excessively large weights.
The bias gradient could either explode or diminish.
Depending on the chosen standard deviation, the network might struggle to learn.
Technique 3: Xavier/Glorot Initialization
Xavier Initialization is beneficial for appropriately scaling weights to avoid them becoming overly large or small, which preserves the effectiveness of the bias.
Sample:
Python
Code Copied!
var isMobile = window.innerWidth “);
editor84294.setValue(decodedContent); // Set the default text
editor84294.clearSelection();
editor84294.setOptions({
maxLines: Infinity
});
function decodeHTML84294(input) {
var doc = new DOMParser().parseFromString(input, “text/html”);
return doc.documentElement.textContent;
}
// Function to copy code to clipboard
function copyCodeToClipboard84294() {
const code = editor84294.getValue(); // Get code from the editor
navigator.clipboard.writeText(code).then(() => {
// alert(“Code copied to clipboard!”);
function closeOutput84294() {
var code = editor84294.getSession().getValue();
jQuery(".maineditor84294 .code-editor-output").hide();
}
// Bind event listeners to the buttons
document.getElementById("copyBtn84294").addEventListener("click", copyCodeToClipboard84294);
document.getElementById("runBtn84294").addEventListener("click", runCode84294);
document.getElementById("closeOutputBtn84294").addEventListener("click", closeOutput84294);
Results:
Clarification:
The preceding code is employed to set the weights of a linear layer using the Xavier (Glorot) Uniform Initialization approach. The bias is initialized to zero, followed by displaying the initialized values.
Influence on Bias:
Weights are equilibrated, enabling the bias to efficiently adjust outputs.
Bias begins at zero to ensure no initial bias towards any neuron.
Contributes to faster convergence and enhanced training stability.
Technique 4: He Initialization
This method is specifically crafted for networks utilizing ReLU, helping mitigate issues related to dying ReLU.
Sample:
Python
“““html
Code Duplicated!
var isMobile = window.innerWidth “);
editor96795.setValue(decodedContent); // Assign the default text
editor96795.clearSelection();
editor96795.setOptions({
maxLines: Infinity
});
function decodeHTML96795(input) {
var doc = new DOMParser().parseFromString(input, “text/html”);
return doc.documentElement.textContent;
}
// Function to copy code to clipboard
function copyCodeToClipboard96795() {
const code = editor96795.getValue(); // Retrieve code from the editor
navigator.clipboard.writeText(code).then(() => {
// alert(“Code copied to clipboard!”);
function closeoutput96795() {
var code = editor96795.getSession().getValue();
jQuery(".maineditor96795 .code-editor-output").hide();
}
// Attach event listeners to the buttons
document.getElementById("copyBtn96795").addEventListener("click", copyCodeToClipboard96795);
document.getElementById("runBtn96795").addEventListener("click", runCode96795);
document.getElementById("closeoutputBtn96795").addEventListener("click", closeoutput96795);
Output:
Clarification:
The aforementioned code is utilized to set the weights of a linear layer employing Kaiming Uniform Initialization. It contributes to enhanced training stability with ReLU activations and initializes the bias to zero.
Effects on Bias:
The bias stays ineffective, as weights are appropriately negated.
It stops neurons from turning inactive in ReLU network architectures.
This results in improved convergence when contrasted with Xavier in deeper networks.
Method 5: Evaluating Training Performance with Varied Initializations
Now let’s assess how bias interacts with different weight initialization techniques throughout training.
Example:
Python
Code Duplicated!
var isMobile = window.innerWidth “);
editor37849.setValue(decodedContent); // Assign the default text
editor37849.clearSelection();
editor37849.setOptions({
maxLines: Infinity
});
function decodeHTML37849(input) {
var doc = new DOMParser().parseFromString(input, “text/html”);
return doc.documentElement.textContent;
}
// Function to copy code to clipboard
function copyCodeToClipboard37849() {
const code = editor37849.getValue(); // Retrieve code from the editor
navigator.clipboard.writeText(code).then(() => {
// alert(“Code copied to clipboard!”);
function hideOutput37849() {
var code = editor37849.getSession().getValue();
jQuery(".maineditor37849 .code-editor-output").hide();
}
// Add event listeners to the buttons
document.getElementById("copyBtn37849").addEventListener("click", copyCodeToClipboard37849);
document.getElementById("runBtn37849").addEventListener("click", executeCode37849);
document.getElementById("closeoutputBtn37849").addEventListener("click", hideOutput37849);
Output (Results May Differ):
Clarification:
The aforementioned code is utilized to establish a basic linear model in PyTorch. It employs various weight initialization techniques (Zero, Normal, and He), calculates the loss for a sample input-output pair, and displays the loss for each initialization method.
Insights:
Zero initialization completely fails (high loss).
Random normal can be effective but may exhibit instability.
Xavier and He initialization are employed to balance bias and weights, which results in enhanced performance.
Summary
Bias holds significant importance in neural networks. It aids models in modifying outputs and effectively learning intricate patterns. Nevertheless, the effect of bias is closely linked to weight initialization. Inadequate weight initialization may lead to biases being perceived as ineffective, slow the model’s learning process, or hinder convergence. Conversely, methods like Xavier and He Initialization facilitate a balanced interaction between weights and bias, fostering stable training and improved performance.
When constructing deep learning models, it is imperative to experiment with a variety of initialization strategies to optimize both weights and bias. A properly initialized network not only trains more rapidly but also generalizes better when faced with unseen data. By comprehending how different weight initializations influence bias, one can make informed choices to enhance the overall effectiveness and precision of the model.
Frequently Asked Questions
1. What is Bias in Neural Networks?
In Neural Networks, Bias is an extra parameter that enables the model to adjust the activation function, assisting it in learning patterns that weights alone may not capture.
2. Why is Bias Significant in Neural Networks?
Bias is significant in Neural Networks as it enhances the model’s flexibility. It permits neurons to activate even when the weighted sum of inputs equals zero. This improves the model’s learning efficiency.
3. How Does Bias Differ from Weights?
Bias differs from weights as weights dictate the connection strength between neurons while bias adjusts the activation function, allowing the model to adapt independently of the input values.
4. What Occurs if Bias is Absent in a Neural Network?
In the absence of bias in neural networks, the model may find it challenging to accurately fit the data, thereby restricting its capacity to learn complex relationships and potentially resulting in overfitting.
How is Bias Initialized and Modified During Training?
Bias is typically initialized to zero or small random values. It gets modified through backpropagation alongside the weights during the optimization process.
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.